


出品|搜狐科技
作者|张雅婷
编辑|杨锦
12月17日,“AI天才少女”罗福莉在离开DeepSeek、加入小米后,首次公开亮相。
在今日举行的小米“人车家全生态”合作伙伴大会上,罗福莉作为小米MiMo大模型负责人,为外界介绍了小米最新开源上线的AI大模型Xiaomi MiMo-V2-Flash,以及她对于AI技术发展的看法。
她认为,AI正在以非线性的方式,重演人类大脑6亿年的进化史。“生物是从行动进化到思考,再进化到语言。但是大模型是先学会了语言,再补齐思考能力,最终补齐对物理世界以及自身的感知。”
罗福莉表示,MiMo-V2-Flash模型虽然总参数只有309B,但已经达到全球开源模型的TOP2。比如,MiMo-V2比DeepSeek-V3.2更便宜,但推理速度约为后者的三倍。
据了解,早在今年4月,小米便推出了首个推理大模型Xiaomi MiMo,由大模型Core团队研发。在今天的演讲中,罗福莉介绍小米大模型Core团队是研究、产品与工程深度耦合的年轻团队,小而美却充满创新精神。
她还回忆称,2020年刚进入大模型领域的时候,国内开源模型距离世界顶尖的闭源模型的差距至少有3年,而现在只剩4个月。“开源本质上是一种分布式的技术加速主义,是实现AGI的普惠化,确保所有人类智慧共同进化的唯一路径。”
曾在DeepSeek、阿里达摩院任职,或被雷军以千万年薪挖角
公开资料显示,罗福莉本科就读于北京师范大学计算机专业,硕士毕业于北京大学计算语言学专业。求学期间,她曾在人工智能领域顶级国际会议ACL上发表了8篇论文,其中2篇为第一作者。
硕士毕业后,罗福莉进入阿里达摩院做人工智能研究,从事预训练语言模型相关的工作,负责阿里达摩院AliceMind开源项目,主导开发了多语言预训练模型VECO。
2022年,罗福莉加入幻方量化从事深度学习相关策略建模和算法研究,后又到DeepSeek担任深度学习研究员,参与研发MoE大模型DeepSeek-V2。
2024年底,有报道称,罗福莉被小米创始人雷军以千万年薪招募,担任小米AI实验室的大模型团队负责人,她也被外界称为95后AI“天才少女”。
今年2月18日,对于外界的炒作,罗福莉在朋友圈发文称:“请互联网还我一片安安静静做事的氛围吧!几年前就说过我并非天才少女,神化一个人的结果就是捧得多高摔得多重! ”
她还表示,一些“low到爆”的AI风自媒体文章充满了事实性错误。“为了流量,为了消费的自媒体们,请收手吧!不要再无差别打扰我家人、朋友、同学乃至初高中班主任了,只想安安静静做难而正确的事情,仅此而已!”
10月14日,小米和北京大学联合署名的论文发表于arXiv,罗福莉也出现在了这篇论文的通讯作者之列。
在上个月,罗福莉正式官宣入职小米。她在朋友圈发文:“智能终将从语言迈向物理世界。我正在Xiaomi MiMo,和一群富有创造力、才华横溢且真诚热爱的研究员,致力于构建这样的未来,全力奔赴我们心目中的AGI。”
小米MiMo跻身全球Top水平?
此前在2025年4月30日,小米公司开源首个推理大模型Xiaomi MiMo,由大模型Core团队研发,通过预训练与后训练联动机制提升推理能力。
昨日晚间,小米发布全新的Xiaomi MiMo-V2-Flash的开源模型,总参数量309B,活跃参数量15B,专为智能体AI设计。
在本次大会上,罗福莉专门介绍了Xiaomi MiMo-V2-Flash的技术细节。
在研发之初,小米团队主要围绕了三个非常关键的问题进行探讨:
第一,当代的智能体必须要有高效的沟通语言,也就是代码能力和工具调用能力。
第二,目前智能体之间的沟通带宽非常低,需要有一个推理效率非常高效的模型,所以需要去重新设计模型结构。
第三,scaling的范式已经逐步从预训练走向后训练,需要想办法激发后训练的潜能。
在这三个问题的驱动下,Xiaomi MiMo-V2-Flash做到了参数量很小,但代码能力和Agent能力,已经达到全球开源模型的TOP2,基本上已经比过了DeepSeek-V3.2,Kimi K2-Thinking等,但这两个模型的母参数量分别是小米的2倍到3倍。
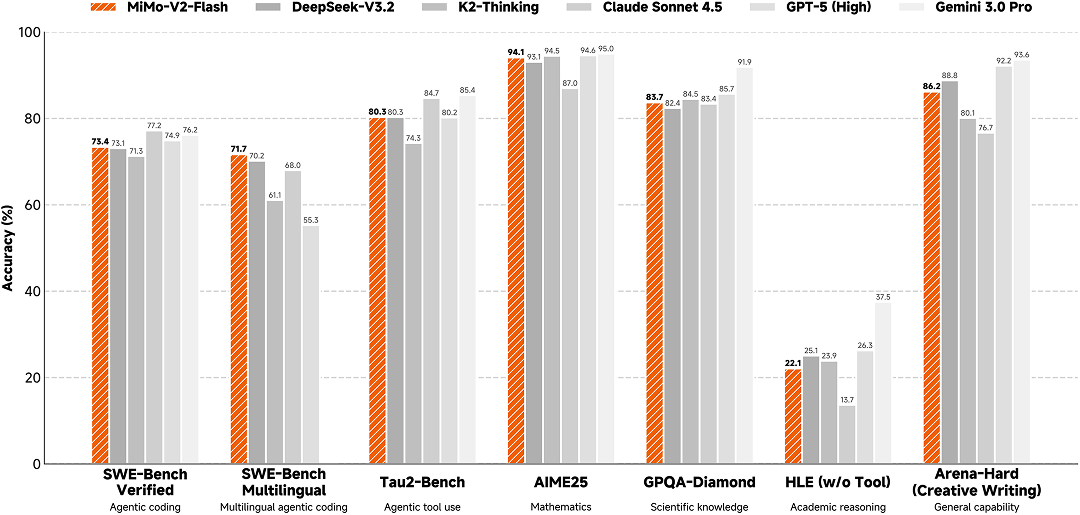
(全球顶尖模型测评基准效果对比,图片来自小米)
MiMo-V2-Flash的 API 定价为: 输入 0.7 元 / 百万 tokens,输出 2.1 元 / 百万 tokens。在全球大致相同水位的顶尖模型速度和成本象限里,MiMo-V2-Flash实现了低成本、高速度。
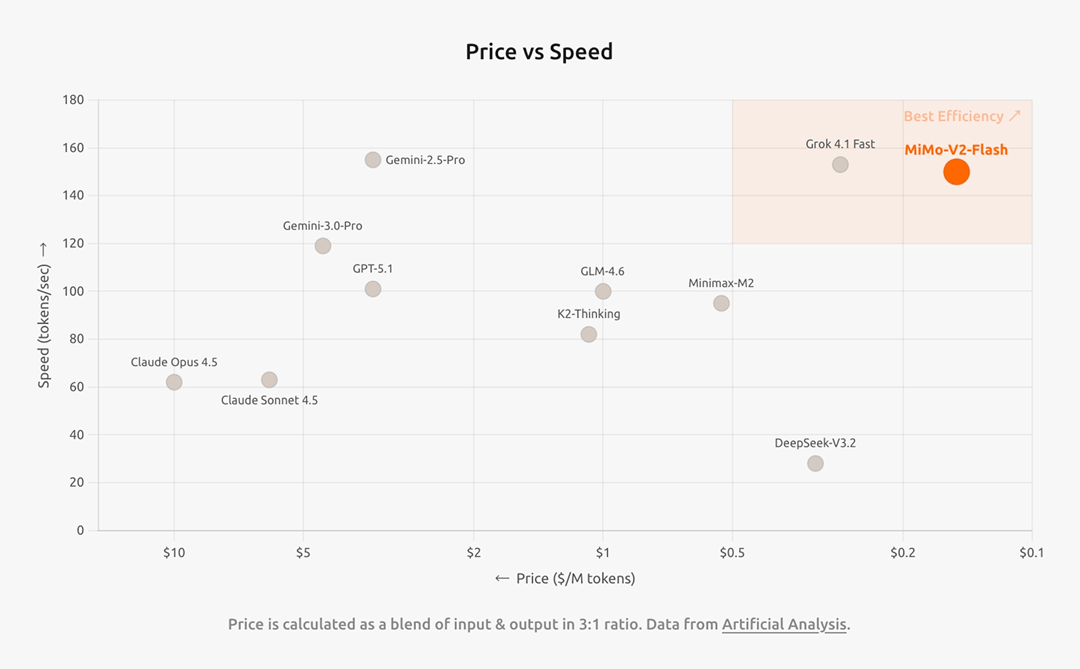
(全球顶尖模型速度 vs 成本,图片来自小米)
比如,MiMo-V2-Flash比DeepSeek-V3.2更便宜,但推理速度是后者的大概三倍左右。MiMo-V2-Flash比肩闭源模型 Claude 4.5 Sonnet,但推理价格仅为其2.5%且生成速度提升至2倍,
罗福莉解释称,MiMo-V2-Flash围绕极致推理效率设计了模型结构,通过3层MTP推理加速并行Token验证,实现了2.0到2.6倍的推理速度提升。
MiMo-V2-Flash的效率提升,是因为模型结构的创新:包括采用5:1的Sliding Window Attention (SWA) 与Global Attention(GA)混合结构,此外引入MTP (Multi-Token Prediction) 训练提升基座能力的同时,在推理阶段通过并行验证MTP Token。
“真正的智能体要跟世界共存”
在本次大会演讲中,罗福莉还阐述了目前大模型的缺陷,以及下一代智能体系统必须具备的能力。
她表示,如果回到生命进化的历程,会发现自然界在构建智能的这个金字塔的时候,其实遵循着非常严密的逻辑。生物演化的规律是先具备了对物理世界的感知,最后才诞生的语言。
但是现在大模型的发展路径其实是跟生物进化路径不同步的,甚至说是一种倒叙、跳跃。大模型是先学会了语言,再补齐思考能力,最终补齐对物理世界的感知。
这是为什么?其实模型智能的产生首先是在语言领域,这不仅仅是一种符号的排列组合,更是人类的思维在文本领域的一个投射,这个投射本质上是一种有损的压缩。
当大模型在海量文本上进行学习,当模型试图把loss(损失)降到最低的时候,我们发现这其实是在压缩人类数十亿年间关于这个世界的一种认知,这种压缩的过程在我们来看就是智能。
所以其实大模型是通过语言的爆发,通过去scaling计算算力、scaling数据,从而理解了人类的思维,但其实它并不真正像人类一样具备对整个物理世界的感知。
罗福莉认为,下一代真正的智能体系统,不是一个语言模拟器,而是需要跟世界共存,必须要具备两个潜能:一是从回答问题变成完成任务,包括记忆能力、推理能力、自主决策规划等方向背后的研究深度都很深。
二是必须要有感知能力,这意味着统一的动态系统是非常有必要的,是为我们去理解整个世界很关键的基础。在这些基础上,我们可以很无缝地将模型去嵌入眼镜上等智能终端,融入到我们的生活里。
大模型本质上是用了算力的暴力美学,直接去攻克了最底层的语言,但是跳过了中间非常多的部分,包括对世界的感知、模拟,以及必须要有实体跟环境产生交互。
这也是为什么大模型其实已经做到了数学和奥林匹克竞赛差不多的水平,也能去模仿莎士比亚风格去写作,但是并不太懂重力这些物理法则的含义,并且有时候经常会产生一些幻觉。
“下一步,我们本质上要打造的并不是一个程序,其实是一个具备物理一致性、时空连贯性的虚拟宇宙,这代表着AI能力的本质跨越。”罗福莉表示,小米的大模型Core团队就是在这样的长期愿景中诞生的。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






